
By Imad Aad, Technical Project Manager, C4DT
*This blog post has been written as part of the Geneva Dialogue on Responsible Behavior in Cyberspace.
Everyone can develop software, and the resulting quality can vary considerably. There is no single ‘right way’ to write code and reach a given goal. Numerous technologies exist with increasing complexities. Like in all disciplines, ‘mistakes happen’, and software development is no exception. The sensitivity may be even worse with software development than in many other fields, since this domain is highly dynamic. If a developer does not keep up with these dynamics, does not have full understanding of the tools at hand, or does not keep updating old code that he/she developed, the code risks getting ‘vulnerabilities’. These are mistakes that are in the code, either from when it was first written or because it has not been updated. These vulnerabilities can be exploited by hackers who can then gain control of the machine where the code is deployed.
These vulnerabilities can propagate far beyond the code’s original purpose, spreading the vulnerability in an unpredictable and uncontrollable manner. Why and how to best tackle this problem? This is what we’ll discuss in the remainder of this blog.
The Critical Role of Component Reuse
Software development heavily relies on reusing components developed by others. For instance, if the application needs to sort a given shopping list alphabetically, the developer does not need to implement the logic of sorting. Sorting is a common function used for many other purposes, not just shopping. It is widely implemented and its performance (speed) has only been improving. The developer does not have to reinvent or re-implement the logic, which risks being suboptimal or even less secure than an implementation vetted for years by thousands of other developers. Instead, he can reuse the ‘Sort’ function and apply it to his shopping list. The sorting function is no exception. Numerous software elements can be reused, and this is a common practice. A web browser can be implemented (re)using only a few lines of code, but the elements reused and their own reused elements can be tens of thousands of lines of code developed by hundreds of other people from different organisations. This is called the ‘software supply chain’: a given end product that reuses and therefore depends on other elements, which in turn depend on other elements, etc.
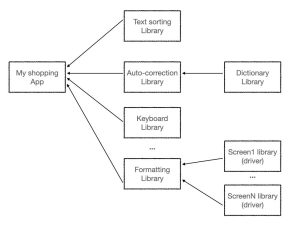
Having these dependencies in mind, it becomes clear that the security of the end product depends on the security of each of the components included in the supply chain. Any vulnerability (as described before) in any of the numerous components of the supply chain propagates and makes the end product vulnerable. These components can originate from anywhere: from the open-source community or from individuals contributing their software for free, who may update their code or not!
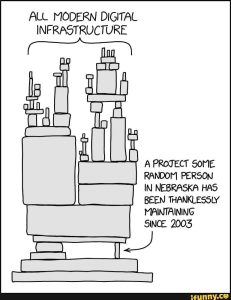
Source: xkcd.
Any hacker who exploits any of the vulnerabilities of any of the elements in the supply chain can potentially compromise the end product. This was the case in several examples in the last couple of years:
- In 2020, hackers managed to insert malware into packages developed by Solarwinds, a US company developing software for managing computers and network infrastructures. Downloaded by 18,000 clients, the infected packages gave the hackers access to the clients’ emails and documents.
- In 2021, hackers managed to distribute their malware using a vulnerability fix made by Kaseya, a US developer of software for managing infrastructures. The infected vulnerability fix gave the hackers access to the end clients’ computers, where they encrypted the data. It is estimated that around 1,000 businesses were impacted, which led them to close for several days.
- Also in 2021, a vulnerability was found in Log4j, an open-source library commonly used to log an application’s activity. Hackers exploited the vulnerability such that computers download and execute their malware. Millions of attacks were made within a few days only.
How to tackle this supply-chain problem and reduce the risks?
As one can guess from the description above, reducing the risks relies on two tasks:
- Keeping track of vulnerabilities
- Keeping track of dependencies (the software supply chain) of the end product application
Keeping Track of Vulnerabilities
According to Synopsys’ 2023 Open Source Security and Risk Analysis Report, ‘More than 95% of 1,700 commercial software contains open-source code and three quarters of code lines are open source […] more than 80% of software contains at least one vulnerability, with almost 50% high-risk ones.’
Despite the scale and the highly dynamic environment, over the last decades, the practice of tracking vulnerabilities (CVEs, Common Vulnerabilities and Exposures) and sharing the information (MISP, Malware Information Sharing Platform) matured well enough, got standardised, which explains its relative ease of use and widespread adoption. This is not yet the case for tracking dependencies (the software supply chain).
Keeping Track of Dependencies
In order to implement good governance, to keep track of the dependencies of the software used, and to keep risks low, organisations must keep an updated software bill of materials (SBOM). This helps to point to vulnerabilities in the components used in the end products they deploy or develop. However, SBOMs show some challenges that hinder their adoption:
- Within an organisation, SBOMs require systematic checks and maintenance of the lists of used, updated, or removed software. Yet, this alone is not enough. The SBOM must link to the dependencies and their respective SBOMs by other providers.
- Between organisations, SBOMs require coordination and standardisation, for instance, for comprehensive, structured naming schemes for software and packages.
Despite the clear need for good governance using SBOMs for improving supply-chain security, SBOMs are not yet common practice.
Beyond Software: Implications for Liability
Is the supply-chain security problem restricted to the software world? The answer is clearly ‘No’. Here are a few examples:
- In 2009, an Air France flight from Paris to Rio de Janeiro plunged into the ocean with 228 people on board. The main cause were air-speed sensors (manufactured by Thales and deployed on its Airbus A330 fleet) that were confusing the pilots.
- In 2013, a large scandal hit many European countries when it was found that beef meat was replaced with horse meat in steaks and ready-made lasagne. Without getting into the details, the supply chain spread over numerous providers and traders from Romania, Cyprus, Netherlands, France, Ireland, Switzerland, Germany, and Norway, even reaching as far as Hongkong.
- In March 2018, a clash over energy between Kosovo and Serbia dropped the oscillation of the whole European power grid, making clocks (the ones that follow the power frequency instead of a built-in oscillator) run as much as six minutes behind across Europe.
Despite the similarities of the supply-chain aspect in these very different domains, liabilities and regulations are not really similar. In the aeroplane and food industry, for instance, it is clear that the end vendor is responsible for all issues, even when they result from the supply chain. In the software world, however, the responsibility is still subject to debate. It may not be realistic for a small company to vet all the components (libraries) and their subsequent ones to make sure the end product is secure. At the same time, it’s not realistic to consider the random Nebraska developer from the figure above liable for not updating his library if he is not paid to do so or when he isn’t even aware of who’s using it, let alone if he’s still active in this domain.
Liability comes along with regulations. In the aeroplane and food industries, for instance, norms and regulations are omnipresent and relatively strict worldwide. In the software industry, this is far from being normalised and regulated. Why?
- Because the food and aeroplane industries are older than the software industry? Maybe.
- Because the software supply chain is more complicated than the food and aeroplane industry supply chains? Maybe not.
- Because food and aeroplane accidents are related to safety and can provoke intoxication and deaths, while the impacts of software supply-chain incidents are not as clear? Maybe.
In recent years, we witnessed an increase in regulations around the world linked to software supply-chain security. However, these are typically related to software used in critical infrastructure (which brings us back to the ‘safety’ factor mentioned above).
On the policy level, the United Nations Group of Governmental Experts (UN GGE) published its final report in 2021 titled Advancing Responsible State Behaviour in Cyberspace, encouraging states to tackle software vulnerabilities (norm 13i) and software supply chain security (norm 13j). The Geneva Dialogue we’re working on covers practices for non-state actors regarding these two norms.
Exploring Alternatives and Realities
Let us take a few steps back and have a high-level look at the problem. Can there be alternative ways of avoiding supply-chain issues and still provide security? For instance:
Why don’t people avoid relying on software supply chains and instead do things on their own, from scratch? Because this is unrealistic. It means that every software developer (or development company) will have to re-implement everything: from capturing what is typed on the keyboard (all possible kinds of keyboards), rewriting all communication protocols (TCP/IP), using all kinds of available network interfaces (wired or wireless) to send information over the channel to receive it on the other side, correct transmission errors, display pixels on the screen (all kinds of available screens) to shape every letter of the alphabet, etc. instead of writing a whole messaging application using a dozen of lines of code. This is not restricted to messaging applications. It applies to all imaginable software. Writing all from scratch is unrealistic. Furthermore, writing things from scratch does not necessarily mean the result is more secure. Rewriting tens of millions of lines of ‘fresh’ code will surely contain more bugs than ‘old’ codes that have been vetted and used for decades, proving their robustness. Reusing software is one of the principles of software design. In general, it is more efficient and more secure.
Is this a transient period, after which we can expect to have bug-free software someday? Not really. We’ll probably improve the software development methods, tools, bug detection, communication about vulnerabilities, keeping up-to-date SBOMs, quickly updating the code we wrote, thus reducing the occurrences of vulnerabilities in software, but it is unlikely that vulnerabilities will become ‘extinct’. They are likely to stay, while hackers will keep exploiting them. Like with health diseases, we have to live with them, learn how to avoid them, reduce their frequency, and decrease their impacts.
Promoting Best Practices: Strategies and Measures
To this end, we can set out good practices on all levels. Without being exhaustive, here are a few examples:
- End users should keep their software (operating system and applications) up to date.
- Software developers may use artificial intelligence (AI) to write better code and find bugs in their software supply chain.
- Organisations should include SBOMs in their governance practice and keep it updated.
- Organisations should ensure secure software development, including strong access control to the code, regular updates, and training.
- Big software developers should contribute back to the (open-source) community, with efforts to check for vulnerabilities and share more reliable code.
- Software quality labels can have a positive impact on the choices of the end users and on the software developers’ incentives for good practices.
- Encourage efforts by organisations like the Open Source Security Foundation.
- Governments and big players should push for security standards, international norms, and regulations.
- Avoid ‘software fragmentation’ due to geopolitical tensions, which are likely to cause collateral damages as well.
Ending with a futuristic note: I started this blog post with ‘Everyone can develop software’, then showed how and why that software may end up in a much larger product through the software supply chain, potentially contributing to its (un)security.
In a similar way, ‘Everyone can write articles’ and share them on the internet. These articles probably end up training AI systems, potentially contributing to their (un)reliability. AI systems can be biased, discriminative, make wrong decisions, etc., based on the information used to train them. This information can be written by another random person in Nebraska who may have changed his mind since he wrote his article. In the coming years, we may witness the need for ‘information bill of materials’ and many of the best practices mentioned above applied to information instead of software.