
In an effort to foster the emergence of a multidisciplinary community around data science for scientific discovery, the Swiss Data Science Center and the University of Bern have joined forces to launch Switzerland’s first Data Science for the Sciences (DS4S) conference.

In collaboration with the FIFDH (FESTIVAL DU FILM ET FORUM INTERNATIONAL SUR LES DROITS HUMAINS), EPFL Pavilions and Ingénieur.e.s du Monde invite you to the screening of the film “Total Trust”, a captivating thriller combining suspense, artificial intelligence and moral dilemmas. The film plunges us into a futuristic universe where new technologies and artificial intelligence have become omnipresent.

Max Schrems is a pivotal figure in international data privacy, lauded for his groundbreaking legal efforts to champion individual data rights. Schrems’ expertise in the field of privacy law and his relentless pursuit of transparency within the digital economy have positioned him as a leading voice in the ongoing dialogue on data ethics. The conference will be moderated by Melanie Kolbe-Guyot, Head of Policy, C4DT

The C4DT launches 3 different initiatives to promote and enable trustworthy and sovereign cloud computing. They build on C4DT’s Conference on Trustworthy and Sovereign Cloud Computing, which was held in September 2023 at the Starling Hotel in St.-Sulpice, and discussions with our partners and conference participants.

EPFL Professor Ebrahimi Touradj will be giving a keynote at the Swiss CyberSecurity Days in Bern on February 21st amongst many other high-profile Cyber Security specialists. He will also participate in a panel on misinformation on February 20th.
February 29th, 2024, 10h00-11h45online Introduction In today’s rapidly evolving technological landscape, the adoption of private cloud solutions has become a strategic imperative for many organizations seeking enhanced security and control over their data. Additionally, by opting for an open-source cloud stack as the foundation of their private cloud solution, they commit to achieving greater transparency (…)

Eurocrypt 2024, the 43rd Annual International Conference on the Theory and Applications of Cryptographic Techniques, will take place at Kongresshaus in Zurich, Switzerland on May 26-30, 2024. Eurocrypt 2024 is organized by the International Association for Cryptologic Research (IACR). The affiliated events will take place at ETH Zurich on May 25-26, 2024.
![[FR] Affaire Taylor Swift: la prolifération des «deepfakes» est jugée «alarmante et terrible». Comment les combattre?](https://c4dt.epfl.ch/wp-content/uploads/2024/01/ts.png)
Créées avec des logiciels utilisant l’intelligence artificielle, des photos et des vidéos pornographiques de la star ont été vues des millions de fois. Face à ce fléau, des solutions techniques et juridiques sont esquissées. Mais leur efficacité est incertaine

The Winter Congress is the annual meeting of the digital society : On Friday evening, March 1st and Saturday, March 2nd, 2024, hackers, programmers, activists and interested parties will come together for the seventh time in the Casino Theater in Winterthur to discuss topics relating to information technology and networking and to exchange their effects on our society.

International Computing Society Recognizes 2023 Distinguished Members for Significant Achievements, and Mathias Payer, Associate Professor at the HexHive Lab, EPFL, is one of the members!
Maya Frühauf of the Education Outreach Department of EPFL asked the C4DT to participate in a 1-day NFT workshop. The Collège Sismondi from Geneva organized a special “semaine informatique” for its students. The C4DT Factory prepared a hands-on workshop to show how to use NFTs. Habiba Zürcher created a project where the students made artwork (…)
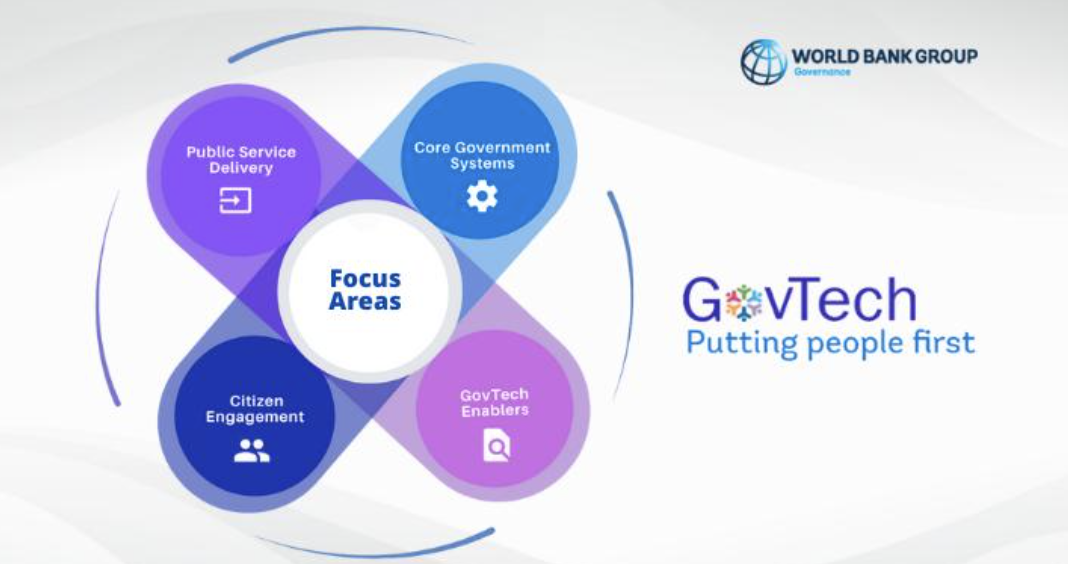
We are pleased to announce that the Center for Digital Trust has joined The World Bank’s GovTech Global Partnership program! This partnership will facilitate the integration of hashtag#academic insights to
improve the effectiveness of public sector operations through technological
applications, significantly enhancing the quality and efficiency of public services.
The Glion Network of Centers is a global network of academic centers for digital trust established in 2023 to facilitate discussion and synergies among participating centers. The goals of this group are to: The Glion Summit, which takes place annually during the final week of August in Glion (an alpine village just above Montreux, Switzerland), (…)

Establishing trust in AI relies on transparency. To realize this goal, we must overcome three critical challenges. How do we cultivate open-source AI, crucial for community development? How do we ensure clarity on data used in model training, handling copyright and bias concerns? How do we promote explainability, clearly delineating where AI is applicable and where it lacks maturity for extensive use? Join our session for a comprehensive exploration of AI transparency and its impact on trust and technology acceptance.
Natural language processing, artificial intelligence, machine learning
The GovTech Hackathon 2024 will cover a range of topics including innovative solutions in data interchange and data use, digital government services for civil society and companies, the networking of public administration with science, and the use of artificial intelligence.
The C4DT launches 3 different initiatives to promote and enable trustworthy and sovereign cloud computing. They build on C4DT’s Conference on Trustworthy and Sovereign Cloud Computing, which was held in September 2023 at the Starling Hotel in St.-Sulpice, and discussions with our partners and conference participants. Each initiative targets a different challenge: C4DT Cloud Initiatives (…)

We are delighted to announce that two additional partners have joined the C4DT community!

[Lang : Fr] A l’occasion de la Journée de la protection des données, la Faculté de droit, des sciences criminelles et d’administration publique de l’Université de Lausanne organise une conférence publique sur le thème « Protection des données et vulnérabilité » en collaboration avec le Préposé fédéral à la protection des données et à la transparence, le Centre universitaire d’informatique de l’Université de Genève et ThinkServices.

Join us for our four-day flagship event at EPFL. Four days of hands-on sessions and topical tracks on machine learning and artificial intelligence with top speakers from around the world. Registration are now open.

Digitization is omnipresent. Formerly a means of optimizing existing processes, information and communication technologies (ICT) have today become vectors of profound transformations. As an individual, organization, economic sector or State, how can we acquire the expertise necessary to evolve with foresight and confidence in this new digital ecosystem?
Join us on a 5-day training to better understand digital technologies and develop a clear overview of the digital ecosystem, as well as understanding the issues, opportunities and risks linked to digital technologies!

Established by the Swiss Federal Department of Foreign Affairs and led by DiploFoundation, with support of the Republic and State of Geneva, C4DT, Swisscom and UBS, the Geneva Dialogue particularly asks how the norms and confidence-building measures (CBMs) might be best operationalised (or implemented) by relevant actors as a means to contribute to international security and peace. So join in on December 7th for the launch of the Geneva Manual – a comprehensive guide on non-state actors’ contributions to the implementation of cyber norms
![[FR] “Les Dangers de TikTok Sur Les Enfants”, Olivier Crochat pour Les Beaux Parleurs, RTS](https://c4dt.epfl.ch/wp-content/uploads/2023/11/Screenshot-2023-11-21-at-16.03.11-e1700579061423.png)
[rts.ch][Lang:Fr] Olivier Crochat, affilié au C4DT et spécialiste en confiance numérique, s’exprime dans l’émission de la RTS “Les Beaux Parleurs” à propos des dangers de l’application TikTok sur les plus jeunes d’entre nous.
Prof. Carmela Troncoso from the SPRING lab, together with Dr. Bogdan Kulynych gave us an introduction to how data can be leaked from any machine learning model. In the afternoon, led by the C4DT Factory team, the partners explored a set of data and discovered how one can measure this leakage, and how one can protect the model from leaking in the first place.